Introduction to Data Structures
Data structures are the foundation of software development, and understanding them is crucial for any software engineer. When learning data structures and algorithms, many people focus on solving LeetCode problems to prepare for coding interviews. However, in real-world scenarios, the value of data structures lies in choosing the right tool for the right problem.
Importance of Data Structures
Many large systems, such as Google Search, Redis, Cassandra, Kafka, Elasticsearch, and Facebook News Feed, are built on familiar data structures. The difference lies in understanding how they work, their pros and cons, and when to use them. In this article, we will explore 15 essential data structures that every software engineer should know.
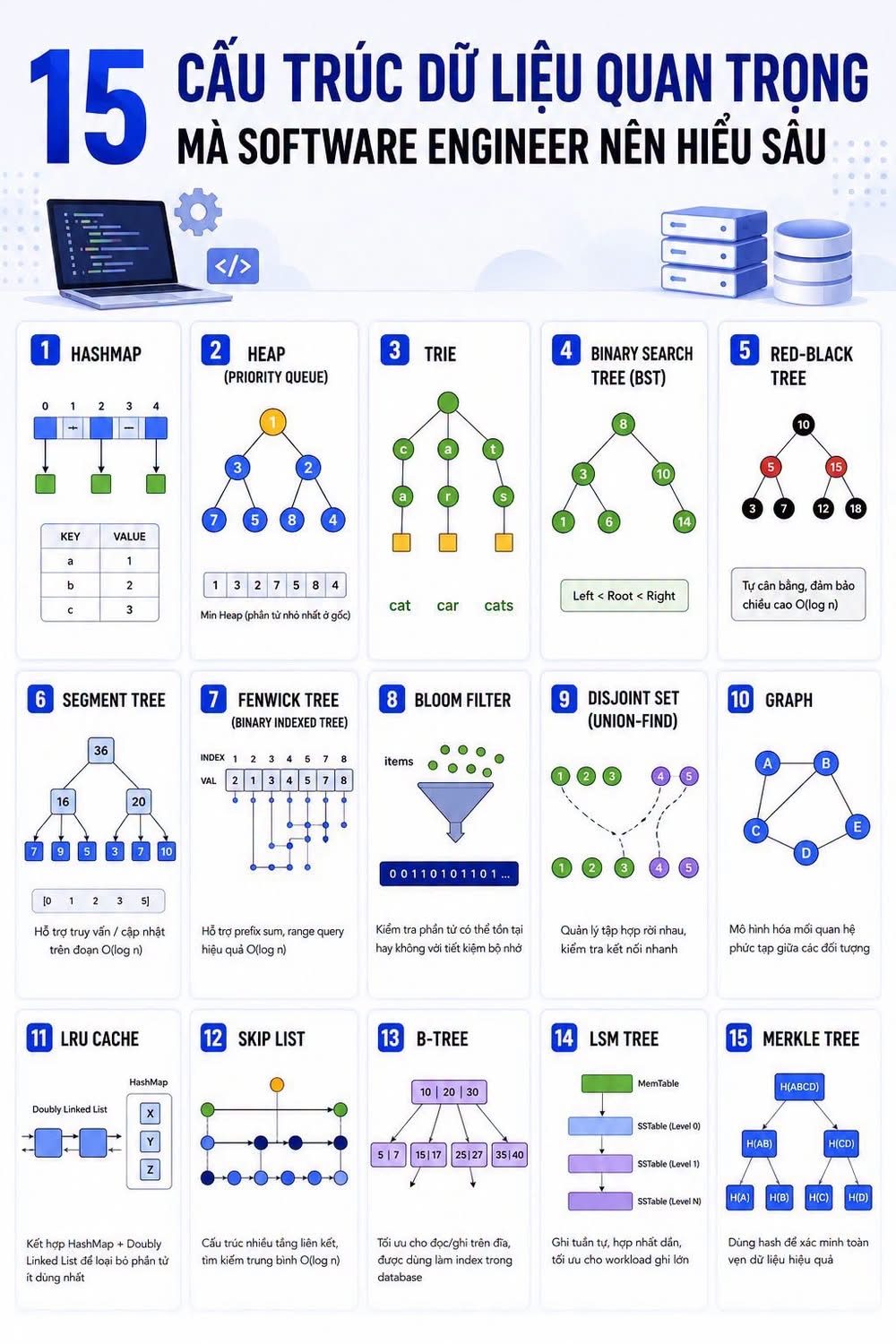
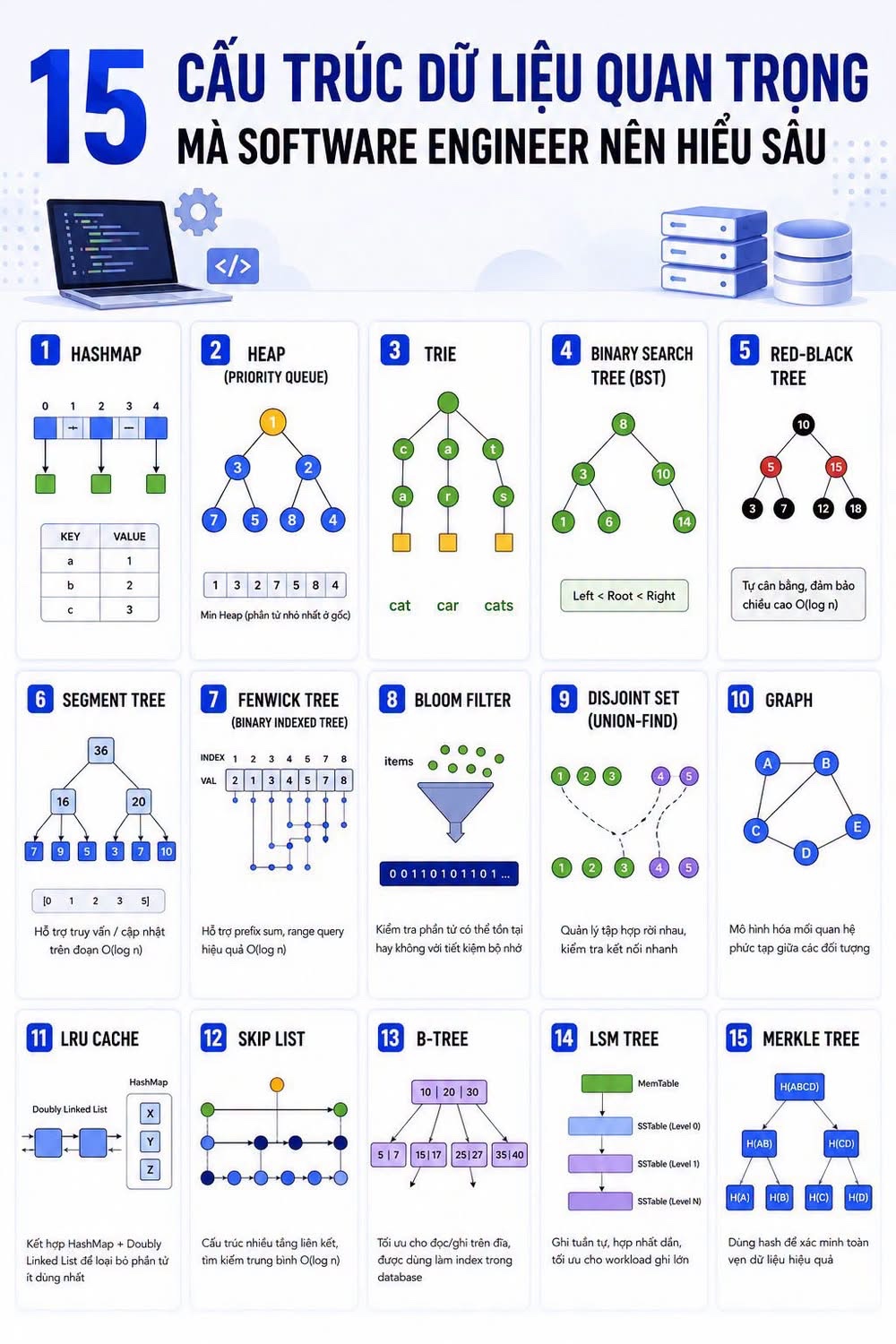
15 Essential Data Structures
1. HashMap: Allows for near-instant data access with an average complexity of O(1). Most problems related to cache, lookup, frequency counting, or indexing involve HashMap. 2. Heap (Priority Queue): Enables systems to efficiently retrieve the highest or lowest priority element. Schedulers, task queues, recommendation engines, and shortest path algorithms often use Heap. 3. Trie: Designed for string processing, Trie is efficient in autocomplete, search suggestions, spell checkers, and dictionaries. 4. Binary Search Tree (BST): Maintains ordered data while supporting search, insertion, and deletion. Although less commonly used in production, BST is essential for understanding more complex balanced structures like AVL Tree and Red-Black Tree. 5. Red-Black Tree: A self-balancing variant of BST, used in many standard libraries and Linux Kernel to ensure stable performance even with large data growth. 6. Segment Tree: Allows for fast query and update of data on a segment, commonly used in competitive programming and real-time analytics systems. 7. Fenwick Tree (Binary Indexed Tree): Efficiently solves prefix sum and range query problems, helping to optimize queries on large datasets. 8. Bloom Filter: Determines whether an element may exist or definitely does not exist, used in Redis, Cassandra, and distributed storage systems to reduce unnecessary disk accesses. 9. Disjoint Set (Union-Find): Manages connected groups, used in network connectivity, clustering, graph processing, and distributed systems. 10. Graph: Not only a data structure but also the foundation of many modern systems, including social networks, recommendation systems, dependency management, routing networks, and knowledge graphs. 11. LRU Cache: Combines HashMap and Doubly Linked List to determine which data to remove when memory is full, commonly used in backend cache layers. 12. Skip List: An alternative to balanced trees, using multiple linked layers to speed up search. 13. B-Tree: Dominates the database world, used in MySQL, PostgreSQL, and traditional databases as the default index structure. 14. LSM Tree: Used in modern storage systems like Cassandra, RocksDB, LevelDB, and ScyllaDB, optimizing write workloads with high speed. 15. Merkle Tree: Used in blockchain, distributed storage, and data synchronization, verifying data integrity using hashes without transmitting the entire dataset.
Practical Takeaways
- Understand the trade-offs between different data structures to choose the best one for your problem.
- Familiarize yourself with the implementation and usage of each data structure.
- Practice solving problems on platforms like LeetCode to improve your skills.
How Data Structures Essentials Works
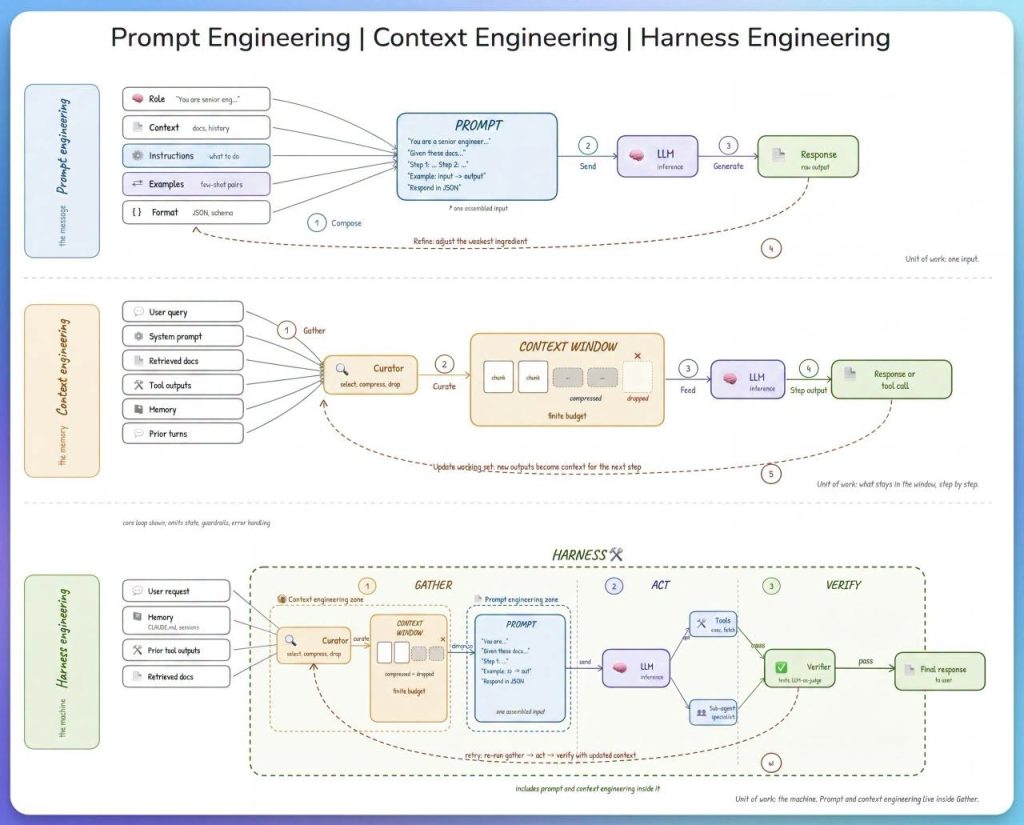
Data Structures Essentials becomes clearer when readers can connect the high-level idea to the underlying workflow. A strong explanation should show the path from input data to useful output, including how information is represented, processed, and evaluated.
For technical readers, the most useful details are the steps that influence quality: data preparation, model architecture, training signals, inference behavior, and feedback loops. Explaining those steps gives the article more depth without forcing beginners into unnecessary jargon.
Key Components to Understand
Most modern AI systems combine several layers: data sources, model architecture, training infrastructure, evaluation methods, and deployment controls. Each layer affects accuracy, latency, cost, and reliability in production.
Readers should also understand the role of prompts, context windows, retrieval systems, monitoring, and human review. These components often decide whether a system is merely impressive in a demo or dependable enough for real workflows.
Limitations and Risks
No technical concept should be presented as magic. The article should explain where the approach can fail, including inaccurate outputs, outdated context, biased data, privacy concerns, unclear evaluation, and operational cost.
These limitations do not make the technology unusable, but they do shape how teams should apply it. Good implementation usually includes validation, logging, security review, and a plan for human oversight when decisions matter.
Implementation Considerations
When teams apply Data Structures Essentials, they need more than a conceptual overview. They should decide what data is allowed, how outputs will be reviewed, what performance metrics matter, and where the technology fits inside an existing workflow.
A practical implementation also needs clear ownership. Product teams define the user problem, engineers manage reliability and integration, security teams review data exposure, and business stakeholders decide what level of automation is acceptable.
Source Images
Conclusion
Data Structures Essentials are crucial for software engineers to understand how large systems are designed and to improve their coding skills. By mastering these essential data structures, developers can better comprehend the architecture of complex systems like Google, Meta, Netflix, or Amazon, and improve their overall software development skills.