
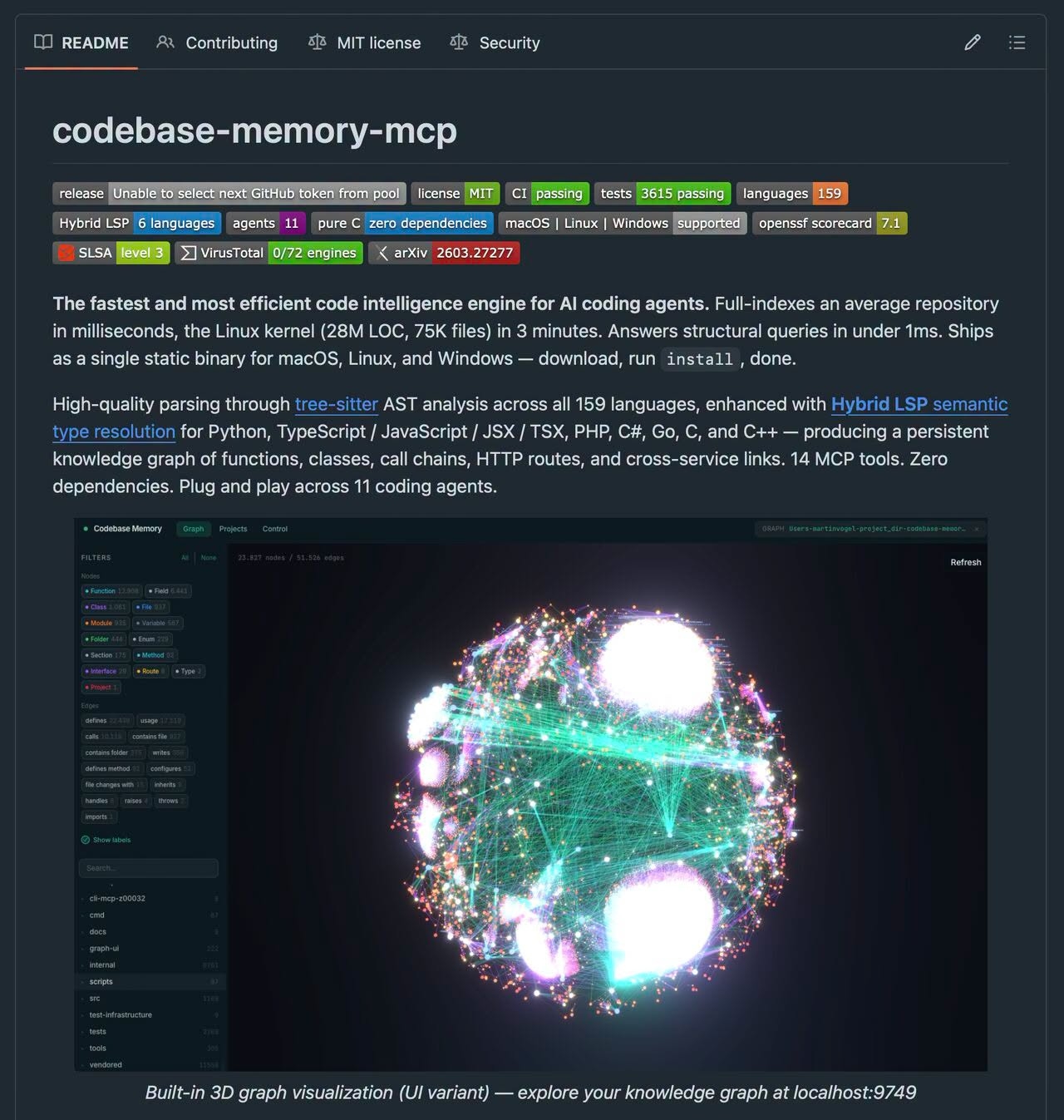
Introduction to Codebase Memory MCP
Codebase Memory MCP is a tool designed to help AI coding agents understand the structure of a codebase quickly and efficiently. This is achieved by parsing the codebase using tree-sitter, which supports 159 languages, and combining it with Language Server Protocol (LSP) to better understand types. The result is a knowledge graph that represents the codebase, allowing the agent to ask structured questions about the code.
How Codebase Memory MCP Works
The idea behind Codebase Memory MCP is simple: instead of having the agent read through hundreds of files, it can ask direct questions about the codebase structure. For example, it can ask where a function is called, how a class is related to a particular part of the code, what dependencies exist between modules, or which files might be affected by a change. This approach significantly speeds up the process of understanding the codebase, which is crucial when working with large repositories.
Features of Codebase Memory MCP
Codebase Memory MCP offers several key features that make it an efficient tool for AI coding agents:
- Parses 159 languages using tree-sitter
- Combines LSP for better type understanding
- Converts the codebase into a knowledge graph
- Provides 14 MCP tools for coding agents
- Indexes repositories quickly and allows for nearly instantaneous queries
- Runs as a single static binary
Comparison with Similar Tools
Codebase Memory MCP shares similarities with tools like CodeGraph and Repowise but stands out due to its speed and lightweight nature. When working with large repositories, the ability to quickly understand the codebase structure is as important as the ability to write code. This makes Codebase Memory MCP a valuable asset for coding agents.
Practical Takeaways
Using Codebase Memory MCP can offer several benefits, including:
- Faster understanding of codebase structure
- Improved efficiency in coding tasks
- Enhanced ability to manage and maintain large repositories
- Better integration with AI coding agents for automated tasks
Key Components to Understand
Most modern AI systems combine several layers: data sources, model architecture, training infrastructure, evaluation methods, and deployment controls. Each layer affects accuracy, latency, cost, and reliability in production.
Readers should also understand the role of prompts, context windows, retrieval systems, monitoring, and human review. These components often decide whether a system is merely impressive in a demo or dependable enough for real workflows.
Limitations and Risks
No technical concept should be presented as magic. The article should explain where the approach can fail, including inaccurate outputs, outdated context, biased data, privacy concerns, unclear evaluation, and operational cost.
These limitations do not make the technology unusable, but they do shape how teams should apply it. Good implementation usually includes validation, logging, security review, and a plan for human oversight when decisions matter.
How to Use This Resource Effectively
A useful article about Codebase Memory MCP should help readers connect the simple explanation, the technical mechanism, and the practical decision they may need to make next. That means the content should not stop at definitions; it should show why the topic matters, where it fits, and how readers can evaluate it responsibly.
For beginners, the most important value is a clear mental model. They should understand the problem the technology solves, the kind of input it receives, the kind of output it produces, and the reason results can vary from one situation to another.
For technical readers, the article should point toward architecture, data quality, evaluation, and deployment tradeoffs. These details explain why two systems with similar demos can behave very differently in production, especially when the data is specialized or the workflow has strict quality requirements.
For business readers, the practical question is not whether the technology is impressive. The better question is whether it can reduce friction, improve decision quality, support a team process, or create a better user experience without adding unacceptable operational risk.
The strongest next step is to compare a short accessible resource with a deeper technical resource, then write down what each one clarifies. That approach gives readers both confidence and caution, which is usually the right balance for fast-moving technology topics.
Readers should also look for examples that show both successful and difficult cases. A balanced example set makes the article more useful because it reveals the boundary between a clean demonstration and a real operating environment.
Finally, every recommendation should connect back to a practical decision. If the article cannot help someone choose what to learn, test, adopt, avoid, or monitor next, it probably needs more context before publication.
Readers should use the linked source to compare the summary against the original implementation details, especially when architecture, tooling, or deployment steps influence the final decision.
- Define the core concept in plain language.
- Identify the main technical components.
- Map the idea to real workflows.
- Check limitations before recommending adoption.
- Use references to verify important claims.
References
These external sources were used to verify the article and provide deeper context.
- Source: GitHubcodebase memory mcp – GitHubOpen original resource
- Source: GitHubcodebase memory mcp – GitHubOpen original resource
Source Images
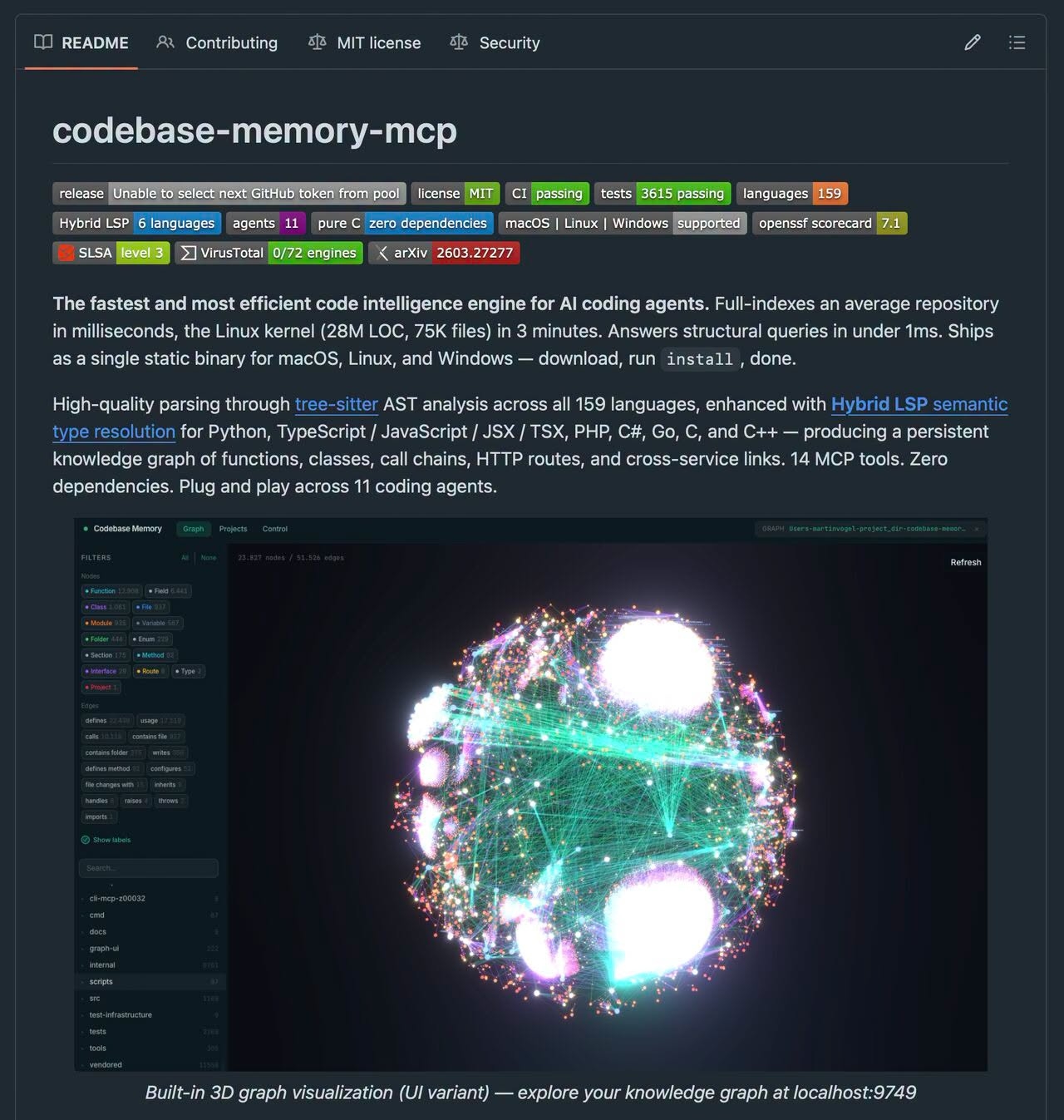
Conclusion
Codebase Memory MCP is a powerful tool for AI coding agents, offering a fast and efficient way to understand codebase structures. Its ability to parse a wide range of languages, combine with LSP for better type understanding, and convert codebases into knowledge graphs makes it a valuable asset for coding tasks. For those looking to improve the efficiency of their coding workflow, especially when working with large repositories, Codebase Memory MCP is definitely worth considering.


